




Мы работаем с огромными объемами данных. По данным Cybersecurity Ventures, исследовательской компании по изучению глобальной киберэкономики, к 2025 году объем хранения данных в мире превысит 200 зеттабайт. Эти данные занимают много места на ограниченных устройствах хранения, таких как твердотельные накопители, вращающиеся диски и ленты (физические и виртуальные). Традиционные методы резервного копирования не заботятся о том, сколько места хранилища они занимают во время работы. Но процессы, которые имеют дело с огромными объемами данных, такие как хранение данных, методы резервного копирования и механизмы восстановления, сильно страдают.
В этой ситуации возникают технологии сокращения объема данных, такие как дедупликация данных и сжатие данных, которые облегчают нагрузку на пропускную способность сети и повышают эффективность для оптимизации хранения данных. Эти технологии широко используется в виртуализации и программном обеспечении для резервного копирования, например, vSAN от VMware осуществляет дедупликацию и сжатие данных на уровне блоков для экономии емкости хранилища. И все же, несмотря на их известность, некоторые недоумевают по поводу принципов их работы и того, какую пользу они принесут для защиты данных.
Что такое дедупликация данных?
Дедупликация данных - это вычислительная техника, используемая для устранения дублированных копий повторяющихся данных. С этой целью дедупликация запускает движок для выявления и устранения избыточных блоков данных.
Как это работает?
Процесс дедупликации проверяет одинаковые куски данных или шаблоны байтов - уникальные и смежные блоки данных, каждому из которых присвоен единый хэш-код, - во всех файлах, каталогах, серверах и типах данных. Эти блоки фиксируются, записываются и сравниваются с другими блоками в текущих данных в процессе анализа. Каждый раз, когда происходит совпадение, лишние блоки данных с тем же хэш-кодом заменяются краткой ссылкой, указывающей на сохраненный блок.
Типы:
Дедупликация данных включает в себя методы на основе файлов и блоков, первый проверяет наличие лишних блоков данных в наборе данных и имеет две вариации: фиксированный размер блока с одинаковой длиной, основанный на размере файла или RAID-массива (обычно 4 КБ), и переменчивый размер блока, меняющийся в зависимости от обрабатываемых данных; второй зависит от проветки на уровне файла и сохраняет только одну копию.
Кроме методов, основанных на различных объектах проверки, существуют еще две категории в зависимости от места их возникновения.
Дедупликация источника описывает дедупликацию, которая происходит около места создания данных. Программное обеспечение для резервного копирования периодически сканирует недавно созданные блоки данных и сравнивает их с теми, что сохранены на сервере резервного копирования, а затем удаляет лишнюю копию в процедуре резервного копирования. Если один из дублированных файлов изменен, программное обеспечение резервного копирования переносит только измененные данные, используя систему "копия при записи".
Целевая дедупликация -это процесс, когда он происходит рядом с местом хранения данных. Движок дедупликации либо располагается выше по потоку как отдельное устройство, либо встраивается в аппаратный массив. Существует два вида доступной целевой дедупликации в зависимости от используемой структуры: дедупликация после обработки и инлайн-дедупликация.
- Дедупликация после обработки: Новые данные изначально сохраняются на устройстве хранения, а затем механизм просматривает данные для поиска дубликатов. Преимущество заключается в том, что нет необходимости задерживать хранение данных до завершения хэш-вычислений и поиска, что повышает производительность хранилища.
- Инлайн-дедупликация: Инлайн-дедупликация выполняет процесс дедупликации в потоке данных до их записи в хранилище. При этом сохраняются только уникальные сегменты данных. Это снижает производительность записи и накладывает ограничения на дедупликацию блоков данных с фиксированным размером. Это также делает данные сразу доступными для восстановления.
Преимущества:
Большая емкость хранилища: Объем хранилища максимально увеличивается благодаря избавлению от дублированных копий. Это помогает компаниям сэкономить место хранилища, а со временем и целое состояние.
Оптимизированное распределение хранилища: С помощью удаления избыточных данных, которые занимали бы место на носителе хранилища, дедупликация данных высвобождает пространство.
Более быстрое аварийное восстановление: Объем данных после дедупликации значительно уменьшается, что позволяет занимать меньше пропускной способности и ускоряет аварийное восстановление, когда время не терпит.
Постоянная проверка данных: При дедупликации данных резервные копии постоянно проверяются логической проверкой благодаря повторяющимся сравнениям.
Что такое сжатие данных?
Сжатие данных - это процесс кодирования информации меньшим количеством битов по сравнению с исходным представлением. Любое сжатие может быть с потерями или без потерь. При сжатии данных с потерями исходные данные теряются, вместе с тем сжатие данных без потерь могут быть восстановлено полностью как исходные данные.
Типы:
Сжатие данных с потерями: При сжатии с потерями удаляется неактуальная или менее важная информация, классификация которой является дискреционной. При этом всегда происходит потеря данных. После сжатия данных с потерями возможно лишь приблизительное восстановление исходных данных.
Сжатие данных без потерь: Также известное как loss-free compression, оно уменьшает количество битов путем поиска и удаления статистической избыточности овновных данных. Поскольку при сжатии без потерь данные не теряются, после распаковки сжатая информация остается такой же, как и исходные данные.
Преимущества:
Экономия времени и ресурсов: Сжатый файл требует меньше времени для передачи и потребляет меньше пропускной способности сети, а также места для хранения.
Более высокий ROI и экономия средств: Сжатые файлы требуют меньшего объема памяти, чем несжатые, что позволяет снизить затраты на хранение и повысить рентабельность инвестиций.
Повышенная производительность: Меньшее потребление полосы пропускания и более высокая скорость передачи данных повышают производительность компаний как при резервном копировании, так и при восстановлении.
Дедупликация данных фильтрует дублированные данные для эффективного резервного копирования с меньшим размером данных, а сжатие данных уменьшает размер данных за счет их сжатия.
Включение технологий сокращения данных с помощью Vinchin Backup & Recovery
Вы можете легко включить дедупликацию и сжатие данных для эффективного сокращения объема данных при настройке резервного копирования виртуальных машин с помощью Vinchin Backup & Recovery. ПО для резервного копирования выполняет дедупликацию и сжатие данных перед сохранением их в резервном хранилище, что уменьшает размер данных как минимум на 50%.
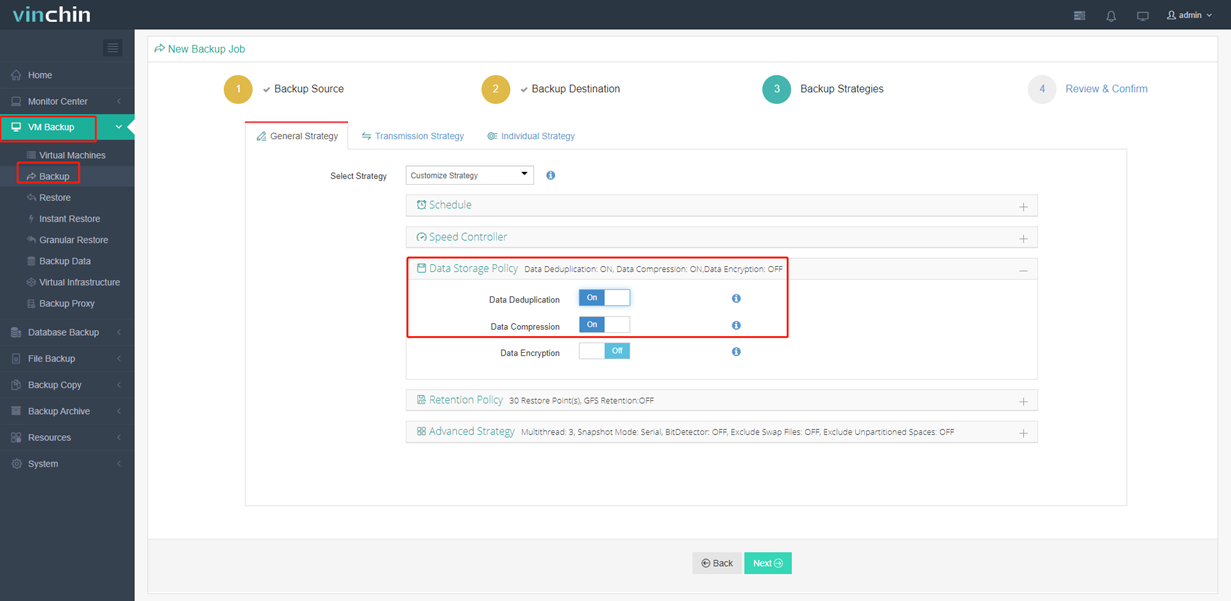
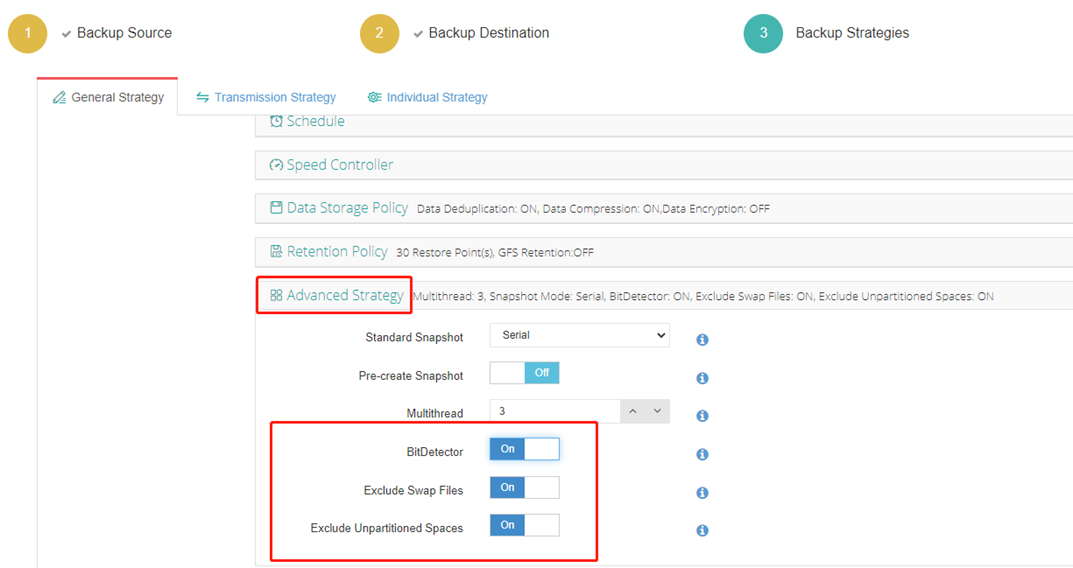
Помимо двух широко используемых функций сокращения данных, BitDetector - еще одна более передовая опция, уникальная разработка компании Vinchin, которая исключает блоки файлов подкачки, неразмеченные пространства и пробелы разделов, а также удаление файлов блоков для пользователей с более строгими требованиями к экономии хранилища данных.
Обобщение
Удаляя дублированные данных и сжимая их до меньшего размера, дедупликация и сжатие данных освобождают ограниченное хранилище резервных копий для более полезных новых блоков данных, позволяют непрерывно проверять данные и обеспечивают более высокое качество восстановления при экономии пропускной способности и ресурсов хранилища. Вы можете воспользоваться 60-дневной бесплатной пробной версией Vinchin Backup & Recovery, чтобы максимально использовать эти две технологии для резервного копирования виртуальных машин, а также оптимизировать результаты экономии хранилища данных до вышего уровня с помощью глубокого извлечения данных, BitDetector.




